In this post, I will explain the subtle nuances among popular OSS NLP libraries, namely Natural Language Toolkit (NLTK), SpaCy, and Spark NLP, and comment on their relative performance and specific applications. My preference for discussing these three libraries is informed by the following observations: how intuitive the libraries seem to be, their general performance, their overall strengths, and how well-maintained their open source repositories are.
The goal with this post is to assist those who are just getting started with NLP, whether your motivation is for your own recreational learning or whether it is to enhance the profitability of your business.
Although the genesis of AI dates back to the 1950s — when Alan Turing published his seminal paper, “Computing Machinery and Intelligence,” hypothesizing whether machines possess the capacity to think, learn and demonstrate reason, and Frank Rosenblatt invented the “perceptron algorithm,” formulating the basis for binary classification — it was not until recently that AI made a quantum leap.
Notwithstanding the significance of such AI pioneers’ contributions, the field of AI had remained largely stagnant for decades, suffering through what was called the AI Winter. The recent advancements in AI, particularly in Deep Learning and its wide range of applications, have become possible not only because of the unprecedented computing power of modern graphics processing units (GPUs) but also thanks to OSS, representing remarkable collective intelligence in the service of AI.
Community-driven open source libraries, such as scikit-learn and pandas, as well as company-backed open source AI frameworks, like TensorFlow and PyTorch, have accelerated AI advancement. They have enhanced the ability of AI practitioners, machine learning engineers, computer and data scientists to create and make use of AI applications in industry, academia, and scientific research. The impact of OSS in AI is also indicated when considering that Python has become the language of choice to represent AI. This is greatly due to Python’s extensive scientific computing ecosystem, which is mainly powered by the flexibility of OSS.
“There’s no way you can have an AI system that’s humanlike that doesn’t have language at the heart of it.”
—Josh Tenenbaum, MIT Brain and Cognitive Sciences
Among the subfields of AI, NLP focuses on computational algorithms for analysis and processing natural human language. Some capabilities include extracting information from textual data, translating between languages, holding conversations, answering questions, classifying sentiments, and generating language. These capabilities create numerous possibilities for applications.
Among those applications are chatbots, enabled by conversational and question answering systems. These systems have become a routine part of how websites function and operate. Some of the many helpful analytical uses are customer reviews that can now be efficiently analyzed using sentiment analysis; research and analysis of textual data in scientific fields greatly benefit from NLP techniques, such as dependency parsing, relation extraction, topic modeling, and word sense disambiguation, among others. In addition to textual data, voice data (aka voice-ai) and speech recognition have gained importance with voice assistants, such as Alexa and Siri, as well as voice-activated GPS, that have become a part of our daily lives, greatly enhancing our user experience.
With the continuous increase in textual data today through a number of online mediums, such as social media, NLP has become indispensable for many domains of knowledge, industry, and businesses alike. It allows us to gain insights into such high volumes of unstructured textual data. Although there are countless examples of the incredible potential of NLP, I want to mention one very recent one that is making a global impact in healthcare.
The entire world has been dealing with the COVID-19 pandemic since early 2020, which still continues to compound exponentially. It soon became clear that this novel virus could be effectively investigated using AI, particularly with NLP. Leading scientific and AI institutions, including Allen Institute for AI, Chan Zuckerberg Initiative, and the National Institutes of Health (NIH), released the COVID-19 Open Research Dataset (CORD-19 dataset, reported in Wang et al., 2020) which is a resource of over 200,000 scholarly articles (100,000 with full text) about COVID-19, SARS-CoV-2, and related coronaviruses.
The dataset, which is open sourced for use by the global research community, aims “to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease.” The White House joined this collaboration and issued a call to action “to the Nation’s AI experts to develop new text and data mining techniques that can help the science community answer high-priority questions related to COVID-19.”
The public release of the dataset was followed by a Kaggle challenge with a symbolic monetary award. Thousands of NLP practitioners and contributors from around the world have submitted their analyses and models based on the dataset. Health researchers and domain experts are getting quick and valuable insights from these models rather than spending time sorting through this huge corpus of textual data. It is a much more efficient way to accelerate research and counter the virus. I have also joined one of the teams, which has quickly reached hundreds of contributors from around the world.
The Kaggle challenge is a clear demonstration of the great power of open collaboration and open science. It is fair to say that the majority, if not all, of the contributors have not been motivated by the award itself, but rather by the good of humanity. They have been contributing their efforts in service of solving a global problem. I encourage you to review the notebooks that have been submitted thus far as they illustrate a variety of useful explorations of the dataset and creative ways of utilizing open source software to power NLP models.
The great potential and widely applicable and practical uses of NLP have already been clear to many, but COVID-19 has highlighted this fact through a case that is affecting the entire world, as well as strengthened the idea that open source, indeed, benefits all.
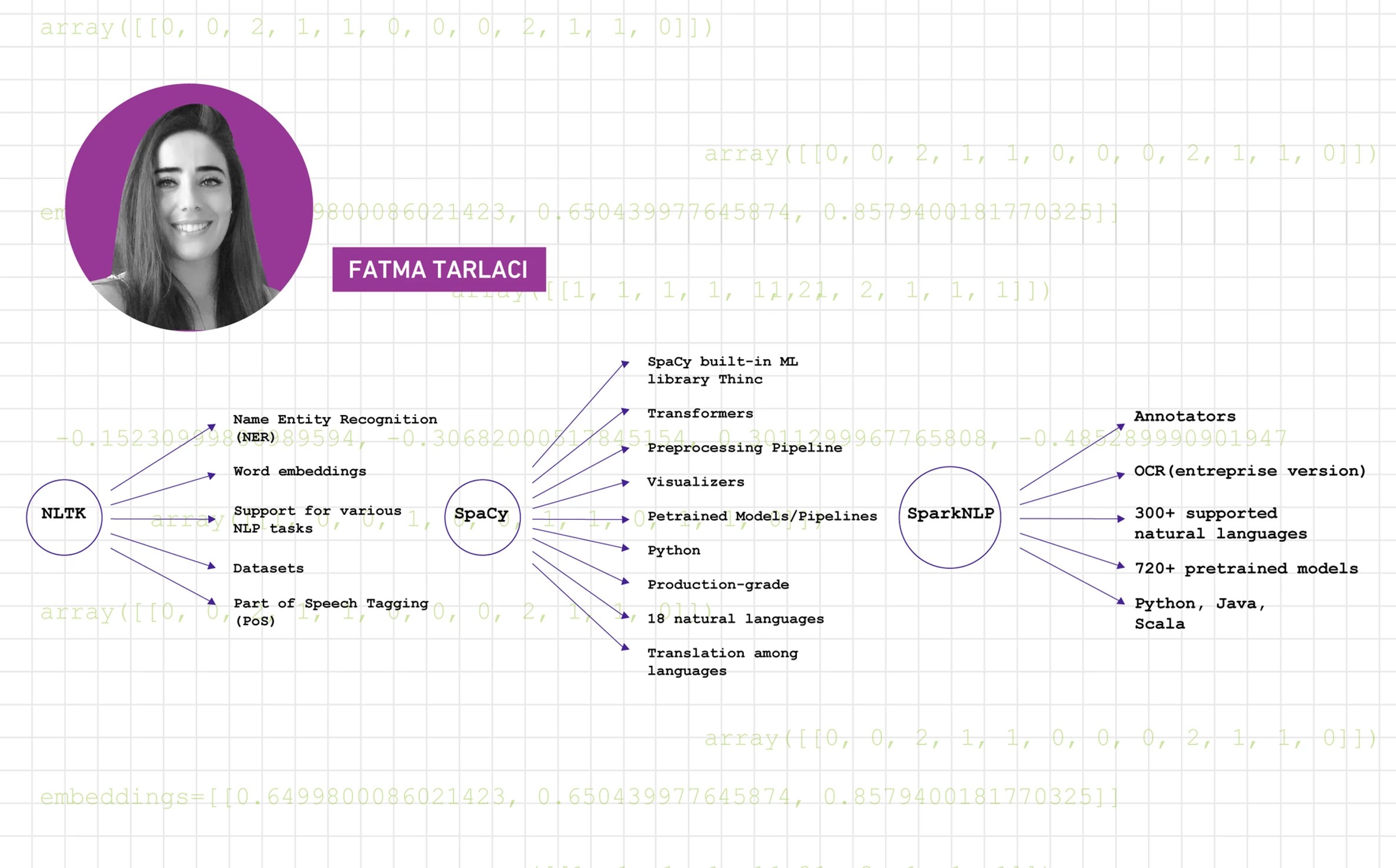
Open source NLP libraries have continued to improve over the last few years. Today, anyone who would like to learn and experiment with NLP techniques, either for fun, research, or business can do so using open source tools and libraries. Those participating in NLP will certainly encounter uses for NLTK, SpaCy, and Spark NLP. Let’s take a look at these libraries.

First released in 2001, NLTK is among the first open source NLP libraries and arguably the most well-known. It provides data preprocessing methods and multiple ways of completing each NLP task, which make it relatively easy to apply to various NLP tasks. Designed by Steven Bird, an academic in computer science and computational linguistics, NLTK’s methodology supports research and teaching in NLP, so the library lends itself nicely to the teaching and learning of NLP techniques. As a testament to its unquestioned importance, it is quite often the first library and resource that those beginning to learn NLP go to. Perhaps for this reason, it is widely used in NLP courses in universities around the world. That is not to say that NLTK has not been used in the industry. On the contrary, its simplicity, flexibility, and computational ease at certain tasks often made NLTK a preferable choice in some NLP applications in industry for years. Continuous support and maintenance are often the concerns with OSS in industry; NLTK has been maintained considerably well since its first release, and version 3.5 was released in 2020, marking a strong sign of maturity for an open source project. Additionally, it has established a sizable and active list of contributors, which is always a good indication of a project’s open source health.
As the field of NLP has remarkably accelerated with the advances in Deep Learning, and stronger than ever language models are created, such as BERT, GPT-3, and RoBERTa, transfer learning with fine-tuning has become a popular approach in NLP applications. However, NLTK does not support the most recent built-in pre-trained Neural Network models making it very difficult to take advantage of transfer learning. NLTK also has proven to be at a disadvantage when it comes to the speed of processing large corpora of textual data. Many ways of doing things, which was once considered a great advantage to have (and might still be in many contexts) and which is considered to be one of NLTK’s strengths, has begun to work against NLTK’s popularity in production ready NLP applications. Many of its algorithms, including those used in tasks, such as tokenization and stemming, can, in fact, be quite slow and laborious, which have made users look for more robust alternatives for production grade NLP applications.
Unlike some of the more recent NLP libraries, NLTK still lacks support for integrated word vectors, which means one needs to handle vectorization by separately integrating models, such as GloVe or Word2Vec, to obtain vector representations of words or work with libraries with built-in word vectors, such as Gensim. This lack of integration is one of the drawbacks of NLTK, especially since transfer learning (the use of pre-trained models) became advantageous for those without powerful computational resources or enough data. This means that the lack of support for the most recent built-in pre-trained Neural Network models partially put this library into the realm of rule-based machine learning approaches to NLP. All that aside, NLTK is still a relevant and useful library to start getting one’s hands dirty with NLP and acts as an indispensable tool, particularly to prepare one for more advanced and robust NLP libraries.

First released in 2015, SpaCy has recently shown considerable growth in terms of popularity among industrial NLP applications for its noticeable robustness and speed. Having thousands of GitHub stars and use metrics, as well as its highly engaged contributors, SpaCy is an excellent example of a healthy open source library. SpaCy’s version, 3.0, has recently been released. This new release features transformer-based pipelines, meaning one can now use any pretrained transformer (fast encoder-decoder model for sequences) to train their own models, which significantly improves SpaCy’s performance. The release also provides better integration with the rest of the NLP ecosystem; SpaCy 3.0 can interoperate with frameworks such as PyTorch, HuggingFace, and TensorFlow.
One of the features that makes SpaCy distinguishable from others is that it earned a reputation for being a fast NLP library, in part from the performance advantages of Cython. Speed, however, is not the only trait SpaCy has to offer. The library also provides a highly optimized way of performing each NLP task. This convenience makes it much more attainable and relatively easy to learn for those considering themselves novices. However, this also causes it to lose some flexibility, which is often a desirable feature.
SpaCy is a self-proclaimed industrial-strength library, which delivers a kind of robustness that puts SpaCy high up on the list of open source NLP libraries. By providing support for deep learning workflows, pre-trained language models, integration of pre-trained word vectors, and built-in visualizers, as well as multilingual tokenization that extends up to 50 languages, SpaCy justifiably stands out among the previously mentioned NLP libraries. A set of examples of how to use SpaCy in your workflows can be found in their docs.

Built on Apache Spark ML APIs and first released in 2017, Spark NLP, developed by John Snow Labs, supports a full spectrum NLP pipeline and has quickly gained the top place among production grade NLP libraries. The last few years have witnessed a historical moment in deep learning and NLP research. State-of-the-art deep learning models have been frequently outmoded in a matter of weeks, and some models have even surpassed human benchmarks. A significant feature that distinguishes Spark NLP from others is that it efficiently incorporates the latest algorithms and pre-trained NLP models, currently the library comes with over 646+ pre-trained pipelines and models, providing its industrial users a competitive advantage. Last week, Spark NLP was released on PyPI and hit 3 million downloads in just a few days.
With Spark NLP one can execute the entire pipeline of NLP from loading, training, and transforming data, building features up to and including an evaluation of the results without having to import other NLP tools, which minimizes the overhead in computation. It offers the streamlined capability to customize and save models to run on a single machine or a cluster. Leveraging the performance of Apache Spark, which is a powerful analytics engine for large-scale data processing on distributed networks, Spark NLP outperforms many others in terms of speed, accuracy, and scalability. The library can take full advantage of powerful systems with multiple GPUs, such as NVIDIA’s DGX 1 or a cloud resource. It supports multiple programming languages (Python, Java, and Scala), as well as natural languages. Spark NLP is a company-backed OSS, which means they have a funded development team that maintains the project. Although it has the smallest number of open source contributors among the previous two, it welcomes contributions from the open source community and shows great potential to stay one of the most comprehensive, enterprise-grade, open source NLP libraries on the free market.

It is certainly an exciting time to be working in the field of AI and NLP. We are in an age where a deep reservoir of information has been collected and systematically improved upon. The impact and importance it has had on society as a whole cannot be understated and never has there been a higher demand for talent. The NLP research community is highly active and the amount of time it takes for a new algorithm to be used in production is now shorter than ever. Powerful algorithms and models are released almost on a daily basis, which, perhaps, is a reflection of the ever-growing amount of unstructured data produced by new AI problems. AI is broadly impacting the world at scale. Among the subsets of this enterprising field, NLP stands out as preeminent and indispensable. NLP applications, in particular, are a critical component and aspect for many sectors and industries ranging from health and education to finance, among others. With their varying learning curves, open source NLP libraries provide great capabilities.
NLP is one of the most important facets of AI at large. At the risk of sounding dramatically philosophical, the importance of NLP is underscored by the reality that language and communication form the most fundamental basis for all civilization, for without language, nothing else of importance could function. Peer-to-peer communication is what allowed the Great Pyramid to be formed by a collective. One could even scale the importance of communication in biological terms all the way down to a cellular or atomic level, where the communication of one cell is dependent on the dissemination and, equally important, the discernment of another. Extrapolating this chain of events, by orders of magnitude, it forms a necessary and cohesive function for the body as a whole. For this reason, among many others, is why NLP is of particular importance to me. I hope you now understand my great enthusiasm for advancements in NLP. Further, I hope you found this post to be enriching and helpful during your future endeavors.




